RAG retrieval 실험에서 처음 확인하고 싶었던 것은 proposed query가 baseline보다 좋은 검색 결과를 가져오는지였다. 그래서 LLM-as-a-Judge로 두 결과를 비교하는 평가 파이프라인을 만들었다. 그런데 swap test를 해보니 약 81%의 케이스에서 judge가 답변 순서에 흔들렸고, 결론은 "어떤 query가 이겼다"가 아니라 "평가자부터 검증해야 한다"로 바뀌었다.
요약
- 문제: 실시간 금융 정보 RAG에서 retrieval 결과를 사람이 매번 판정하기 어려웠다.
- 판단: baseline query와 proposed query의 검색 결과를 LLM judge로 비교하되, 같은 쌍을 A/B와 B/A 순서로 모두 평가했다.
- 결과: 초기 결과만 보면 proposed query가 우세했지만, swap test에서 약 81% 위치 편향이 드러났다.
- 배운 점: LLM-as-a-Judge는 평가 자동화 도구이지 정답 기계가 아니다. retrieval 품질을 평가하려면 judge의 안정성도 같이 검증해야 한다.
상황
학부 연구생 프로그램에서 실시간 금융 정보 RAG의 검색 품질을 평가하는 파이프라인을 만들었다. 목표는 baseline query와 proposed query가 가져온 검색 결과 중 어느 쪽이 더 유용한지 비교하는 것이었다.
RAG에서 retrieval은 단순히 문서를 많이 가져오는 문제가 아니다. 질문에 답하는 데 필요한 근거가 있는지, 최신 금융 맥락을 반영하는지, 불필요한 문서가 섞이지 않았는지를 봐야 한다. 정답 문서가 미리 라벨링되어 있지 않다면 recall이나 precision만으로 판단하기 어렵다.
그래서 LLM을 judge로 세웠다. 여기서 말하는 judge는 fine-tuned model이 아니라 평가 기준과 출력 형식을 prompt로 준 비교 평가자다.
처음 만든 평가 파이프라인
파이프라인은 단순했다.

- 같은 입력에서 baseline query와 proposed query를 만든다.
- 각 query로 검색 결과를 가져온다.
- LLM judge가 두 결과를 비교한다.
- 같은 쌍을 A/B, B/A 순서로 한 번씩 평가한다.
- 두 평가가 같은 실제 승자를 가리킬 때만 승패로 인정한다.
처음 기대는 proposed query가 더 좋을 것이라는 쪽이었다. 역할 부여, 단계적 사고, 금융 맥락을 query 생성에 넣었기 때문이다.
초기 judge 결과만 보면 이 기대는 맞는 것처럼 보였다.
| Decision | Count | Ratio |
|---|---|---|
| Proposed win | 38 | 59.4% |
| Baseline win | 25 | 39.1% |
| Tie | 1 | 1.6% |
이 숫자만 보면 "proposed query가 더 낫다"고 말하고 싶어진다. 하지만 그 전에 더 중요한 질문이 있었다.
이 judge는 공정한가?
Swap test에서 결론이 바뀌었다
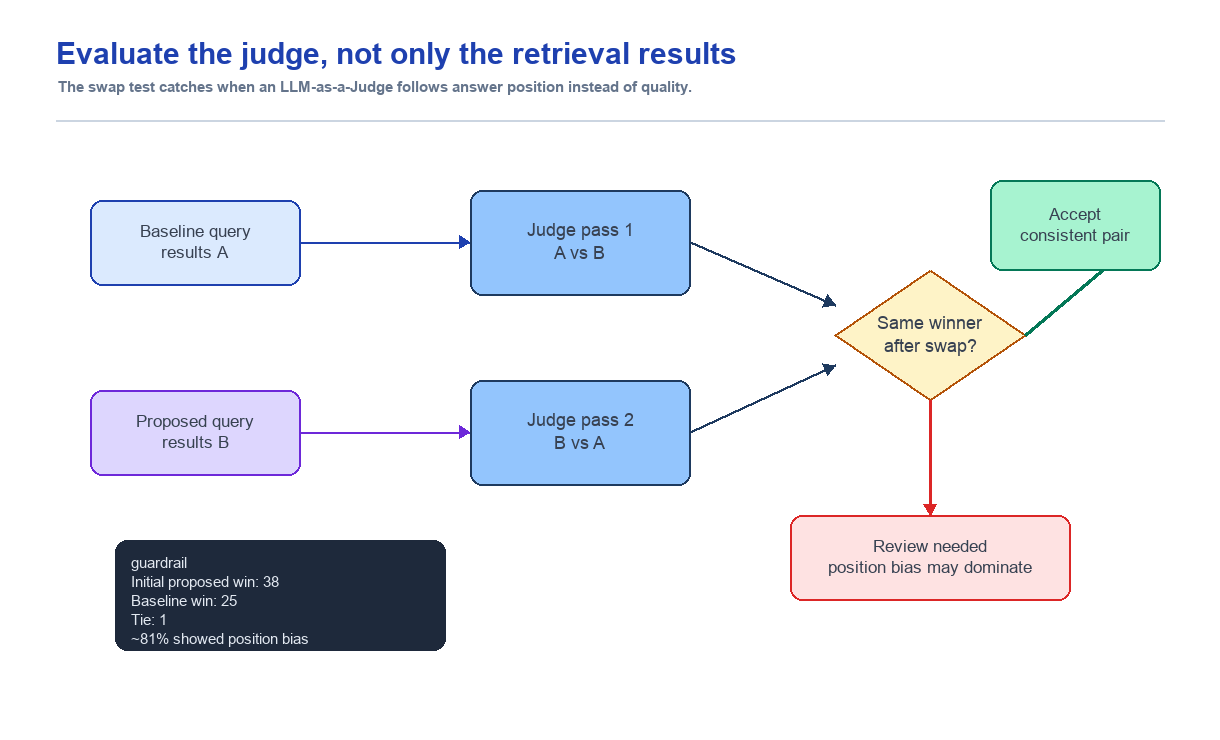
LLM judge가 두 결과를 비교할 때, 같은 내용이라도 어느 쪽을 먼저 보여주느냐에 따라 판단이 달라질 수 있다. 그래서 같은 쌍을 두 번 평가했다.
1차: A vs B
2차: B vs A
두 번 모두 같은 실제 답변을 고르면 consistent
순서를 바꿨더니 승자가 바뀌면 position-biased최종 발표자료 기준으로 약 81%의 케이스에서 위치 편향이 발생했다.

이 결과가 실험의 중심을 바꿨다. proposed query가 좋아진 것인지, judge가 앞에 놓인 답변을 더 자주 고른 것인지 분리할 수 없었다. 평가 자동화를 하려다 평가자 자체가 불안정하다는 증거를 먼저 본 셈이다.
왜 이런 일이 생겼나
위치 편향은 두 결과가 비슷하게 그럴듯할 때 더 잘 드러난다. A와 B의 품질 차이가 크면 judge도 비교적 안정적으로 판단한다. 하지만 둘 다 충분히 좋아 보이면 judge는 실제 retrieval 품질보다 다른 신호에 흔들릴 수 있다.
- 먼저 제시된 답변
- 더 길고 구조화된 답변
- 더 최근 정보처럼 보이는 문장
- 더 자신감 있는 표현
- judge prompt의 작은 표현 차이
이 지점에서 LLM-as-a-Judge를 보는 관점이 바뀌었다. 사람 평가를 완전히 대체하는 도구가 아니라, 싸고 빠르게 후보를 줄여주는 평가 시스템으로 봐야 했다. 시스템이라면 그 시스템의 failure mode도 같이 검증해야 한다.
해결한 방식
평가 파이프라인을 더 보수적으로 바꿨다.
| A/B result | B/A result | Final decision |
|---|---|---|
| A wins | A wins | A wins |
| B wins | B wins | B wins |
| A wins | B wins | Review needed |
| Tie | Any | Review needed |
| Any | Tie | Review needed |
이 방식은 승패를 많이 만들어내지 않는다. 대신 judge가 흔들린 케이스를 결과에서 분리한다. 자동화의 목적을 "빨리 결론 내기"가 아니라 "믿기 어려운 결론 걸러내기"로 바꾼 것이다.
검증
검증은 query 성능만 보지 않고 judge 일관성을 같이 봤다.
- baseline/proposed 검색 결과를 같은 기준으로 judge에 넣었다.
- 같은 쌍을 A/B와 B/A 순서로 모두 평가했다.
- 실제 답변 기준으로 승자가 유지되는지 확인했다.
- 충돌하는 케이스는 억지로 승패 처리하지 않고 review-needed로 분리했다.
이렇게 하면 "proposed query가 몇 % 이겼다"는 숫자는 덜 화려해진다. 대신 남은 승패는 judge 위치 편향을 한 번 통과한 결과가 된다.
다음에는 이렇게 판단한다
- LLM-as-a-Judge를 쓰면 평가 대상만 보지 않고 judge의 안정성도 먼저 본다.
- pairwise comparison에서는 A/B와 B/A swap test를 기본값으로 넣는다.
- 한 번의 judge 결과만으로 query strategy의 우열을 말하지 않는다.
- 두 결과가 비슷하게 좋은 케이스는 tie보다 review-needed로 남겨 사람 검토 후보로 분리한다.
- 평가 자동화의 목표는 결론을 많이 만드는 것이 아니라, 믿을 수 없는 결론을 걸러내는 것이다.
