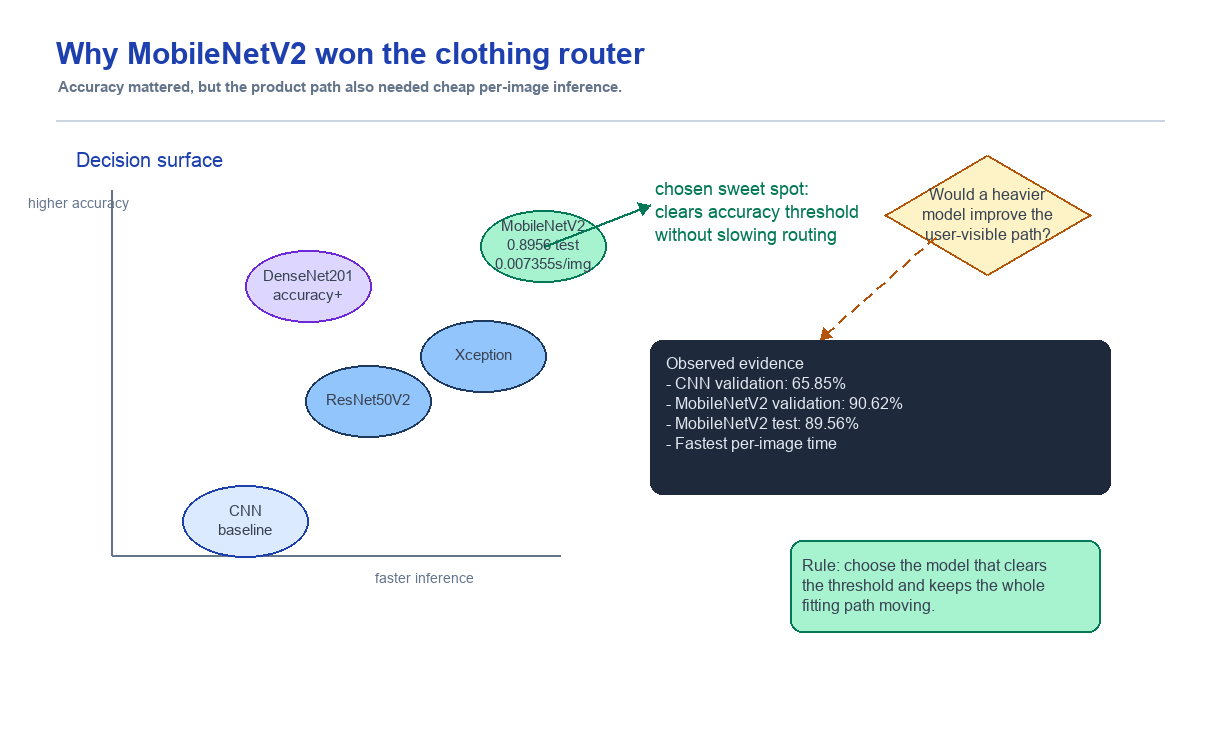
ThatzFit의 의류 분류기는 모델 성능을 보여주는 기능이 아니라 가상 피팅으로 들어가기 전 routing gate였다. 처음에는 test accuracy가 가장 높은 DenseNet201을 고르는 것이 자연스러워 보였지만, 실제 제품 병목은 분류가 아니라 뒤의 virtual try-on이었다. 그래서 최종 판단은 "가장 높은 정확도"가 아니라 "치명적 라우팅 실패를 줄이면서 가장 가볍게 지나가는 모델"로 바뀌었다.
요약
- 문제: 의류 이미지를 상의/하의 등 적절한 가상 피팅 흐름으로 보내는 빠른 routing model이 필요했다.
- 판단: 90% 안팎의 정확도를 threshold로 두고, 그 이후에는 downstream 비용과 추론 시간을 더 크게 봤다.
- 결과: DenseNet201은 test accuracy가 더 높았지만 MobileNetV2가 validation accuracy, inference time, 학습 반복 비용의 균형이 좋았다.
- 배운 점: 모델 선택은 leaderboard가 아니라 제품에서 그 모델이 틀렸을 때 어떤 일이 벌어지는지까지 포함한 의사결정이다.
상황
ThatzFit에는 사용자가 올린 의류 이미지를 적절한 가상 피팅 흐름으로 보내기 위한 분류기가 필요했다. 예를 들어 바지 이미지는 하의 피팅 쪽으로, 셔츠나 아우터 이미지는 상의 피팅 쪽으로 보내야 한다.
처음에는 간단한 CNN baseline을 만들고, 이후 ImageNet으로 사전 학습된 여러 전이 학습 모델을 비교했다. 최종 후보는 성능만 가장 높은 모델이 아니라 서비스 안에서 빠르게 판단할 수 있는 모델이어야 했다.
문제
의류 분류는 그 자체로 최종 사용자 경험의 핵심 작업은 아니다. 사용자가 실제로 기다리는 시간의 대부분은 가상 피팅 모델에서 발생한다. 그래서 분류기는 충분히 정확해야 하지만, 너무 무겁게 만들면 전체 피팅 흐름을 더 느리게 만든다.
이번 실험의 기준은 두 가지였다.
- 정확도는 실무에서 쓸 수 있을 만큼 높아야 한다.
- 정확도가 비슷하다면 추론 시간이 짧은 모델을 선택해야 한다.
데이터
데이터셋은 총 4,500장의 의류 이미지로 구성했다. 90%인 4,050장은 학습에 사용하고, 10%인 450장은 테스트에 사용했다.
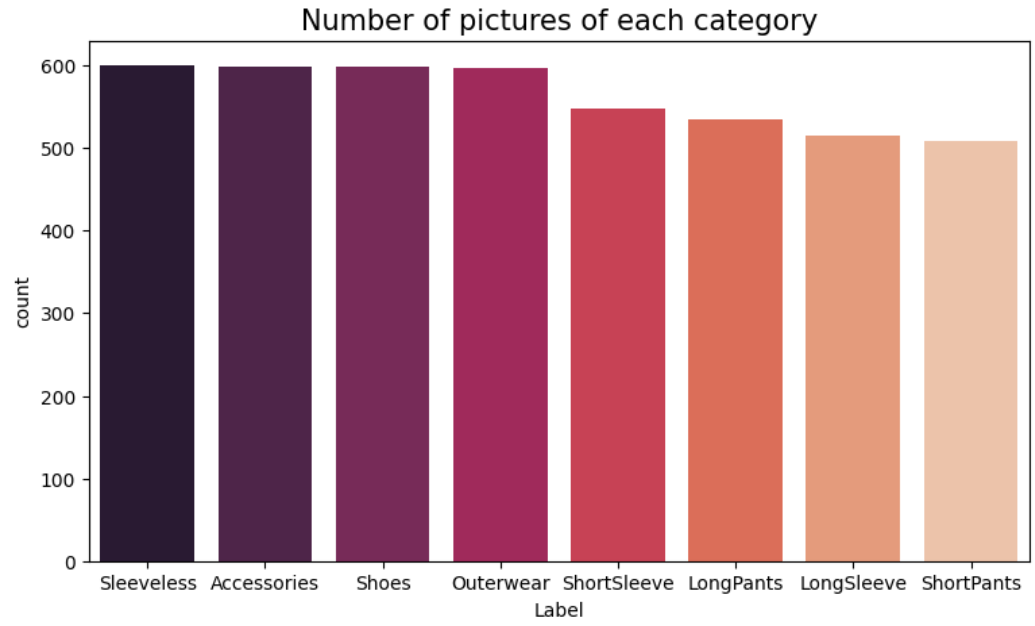
분류 클래스는 8개였다.
- LongPants
- Sleeveless
- Outerwear
- Accessories
- ShortPants
- ShortSleeve
- Shoes
- LongSleeve

학습 과정에서는 과적합을 줄이기 위해 회전, 확대/축소, 이동, 좌우 반전 같은 이미지 증강을 적용했다.
기준
이번 의사결정에서는 지표를 두 종류로 나눴다.
첫 번째는 임계값 기준 지표(threshold-based metric)다. 정확도는 90% 안팎이면 실무 적용 가능성이 있다고 봤다. 이 기준은 모델이 의류 라우팅을 크게 틀리지 않을 정도의 신뢰도를 보장하기 위한 최소선이다.
두 번째는 최적화 기준 지표(optimization metric)다. 추론 시간은 낮을수록 좋다. ThatzFit의 전체 흐름에서는 이미지 분류보다 VITON 기반 가상 피팅이 훨씬 무겁기 때문에, 분류 단계는 가능한 한 빠르게 끝나야 한다.
그래서 최종 선택 기준은 이렇게 잡았다.
정확도가 90%에 가깝거나 넘는 모델 중에서, 추론 시간이 가장 짧은 모델을 선택한다.
Baseline
먼저 간단한 CNN baseline을 학습했다. 이 모델은 2개의 Conv2D 레이어와 MaxPooling 레이어를 사용했고, 마지막에 Dense 레이어로 8개 클래스를 분류했다.
10 epoch 학습 결과는 다음과 같았다.
| Model | Training Accuracy | Validation Accuracy |
|---|---|---|
| CNN baseline | 97.85% | 65.85% |
학습 정확도와 검증 정확도 차이가 컸다. baseline은 빠르게 만들 수 있었지만, 실제 서비스에 넣을 모델로는 부족했다.
모델 비교
전이 학습 모델은 ImageNet pretrained weight를 사용하고, 분류 head만 새로 붙여 학습했다. 실제로는 13개 pretrained 모델을 비교했고, 아래는 성능이 준수했던 모델들이다.
추론 시간은 같은 테스트셋 450장을 한 번 예측하는 데 걸린 전체 시간으로 기록했다. Per Image Time은 이 전체 시간을 테스트 이미지 수로 나눈 값이다. 따라서 아래 수치는 모델 간 상대 비교용이며, 실제 API 응답 시간은 서버 장비, 배치 크기, 이미지 전처리 방식에 따라 달라질 수 있다.
| 모델 | Val Accuracy | Test Accuracy | Training Time | Inference Time | Per Image Time |
|---|---|---|---|---|---|
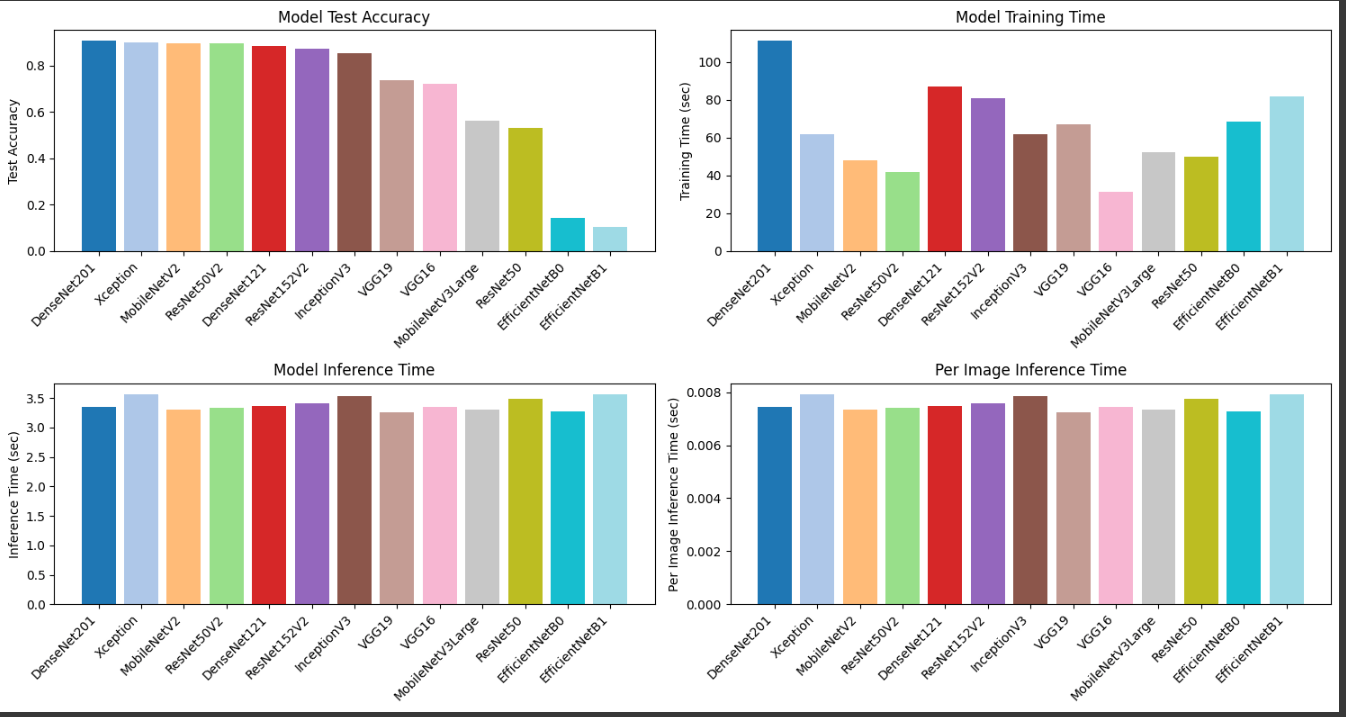
| DenseNet201 | 0.8988 | 0.9067 | 111.38s | 3.3523s | 0.007450s |
| Xception | 0.8815 | 0.9000 | 62.02s | 3.5610s | 0.007913s |
| MobileNetV2 | 0.9062 | 0.8956 | 48.22s | 3.3096s | 0.007355s |
| ResNet50V2 | 0.8963 | 0.8933 | 41.77s | 3.3293s | 0.007399s |
| DenseNet121 | 0.8741 | 0.8822 | 86.92s | 3.3616s | 0.007470s |
DenseNet201은 test accuracy가 가장 높았다. 하지만 추론 시간과 학습 시간이 더 길었다. MobileNetV2는 test accuracy가 90%에 아주 살짝 못 미쳤지만, validation accuracy는 90%를 넘었고 추론 시간이 가장 짧았다.
MobileNetV2 선택 이유
MobileNetV2를 선택한 이유는 세 가지였다.
첫째, 정확도가 충분히 높았다. MobileNetV2는 validation accuracy 90.62%, test accuracy 89.56%를 기록했다. 목표로 잡은 90% 기준에 거의 도달했고, 다른 모델들과 비교했을 때 실무적으로 큰 차이가 없었다.
둘째, 추론 시간이 가장 짧았다. 전체 추론 시간(inference time)은 450장 기준 3.3096초, 이미지당 시간은 0.007355초였다. 이 분류기는 가상 피팅 전에 지나가는 라우팅 단계이므로 이 지점에서 시간을 아끼는 것이 전체 사용자 경험에 더 맞다.
셋째, 학습 시간도 짧았다. 48.22초로 성능이 비슷한 모델들보다 가볍게 학습할 수 있었다. 실험 반복 속도와 운영 비용을 생각하면 이 점도 중요했다.
추가 평가
MobileNetV2를 7 epoch 추가 학습한 뒤 class별 precision, recall, F1-score를 확인했다.
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| Accessories | 0.93 | 0.93 | 0.93 |
| LongPants | 0.94 | 0.94 | 0.94 |
| LongSleeve | 0.77 | 0.84 | 0.80 |
| Outerwear | 0.95 | 0.79 | 0.86 |
| Shoes | 0.98 | 0.97 | 0.98 |
| ShortPants | 0.92 | 0.94 | 0.93 |
| ShortSleeve | 0.90 | 0.90 | 0.90 |
| Sleeveless | 0.89 | 0.94 | 0.91 |
최종 지표는 다음과 같았다.
| Metric | Result |
|---|---|
| Accuracy | 90.89% |
| Weighted Precision | 91% |
| Weighted Recall | 91% |
| Weighted F1-Score | 91% |
시각화 결과
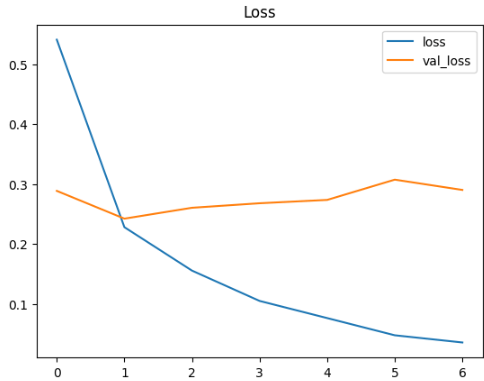
7 epoch 동안 학습 정확도는 98.51%, 검증 정확도는 91.60%에 도달했다.
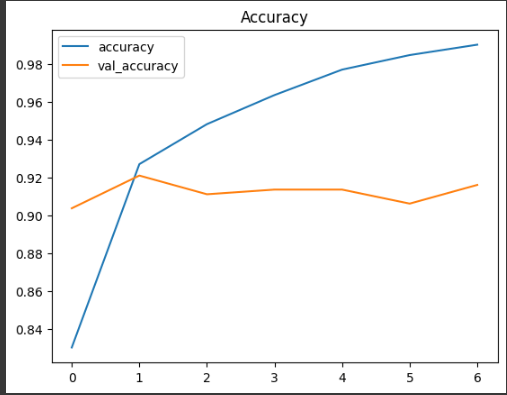
손실 함수는 학습 손실과 검증 손실 모두 안정적으로 감소했다. 다만 약간의 과적합은 보였다. 이 데이터는 실제 서비스에서 들어올 쇼핑몰 도메인 이미지와 가까운 target data라서, 당시에는 이 정도 과적합을 치명적 문제로 보지는 않았다.
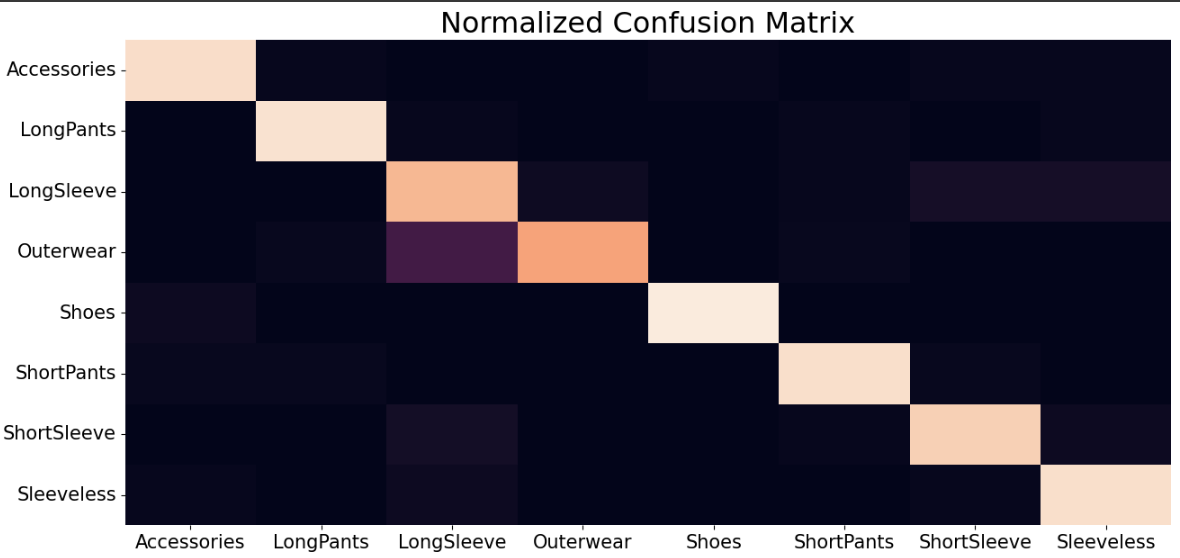
혼동 행렬에서는 LongSleeve와 Outerwear 사이에 약간의 혼동이 있었다. 하지만 ThatzFit의 비즈니스 로직에서는 둘 다 상의 가상 피팅 흐름으로 보내질 수 있다. 즉, 모델 관점에서는 오분류지만 서비스 라우팅 관점에서는 치명적인 실패가 아니다.
배포 형태
모델은 서버에서 로드할 수 있도록 전체 모델과 weight 파일을 각각 저장했다.
model.save("mobilenet_v2_fashion_classifier.h5")
model.save_weights("mobilenet_v2_fashion_classifier.weights.h5")이 방식은 배포 초기에 단순하다. 다만 실제 운영으로 가려면 모델 파일 버전 관리, 입력 이미지 전처리 고정, 클래스 라벨 매핑(class label mapping) 고정, 추론 환경(inference environment) 재현성이 같이 관리되어야 한다.
배운 점
이 실험에서 중요한 점은 “가장 높은 정확도”가 항상 “가장 좋은 선택”은 아니라는 것이다. DenseNet201은 test accuracy가 더 높았지만 ThatzFit의 병목은 의류 분류가 아니라 가상 피팅이다. 분류기는 충분히 정확하고 빨라야 한다.
또 하나의 포인트는 오분류의 비용을 모델 지표만으로 판단하면 안 된다는 점이다. LongSleeve와 Outerwear 혼동은 분류 리포트(classification report)에서는 손실이지만, 둘 다 상의 피팅으로 이어진다면 제품 영향(product impact)은 작다. 모델 평가는 항상 이후 제품 동작(downstream behavior)과 같이 봐야 한다.
다음에는 이렇게 판단한다
의류 분류처럼 downstream routing에 쓰이는 모델은 최고 정확도만으로 고르지 않는다. 먼저 어떤 오분류가 실제 사용자 실패로 이어지는지 보고, 치명적인 실패와 허용 가능한 혼동을 나눈다.
MobileNetV2는 정확도와 추론 시간 사이에서 가장 균형 잡힌 선택이었다. 최종 테스트 정확도는 90.89%까지 확인했고, weighted precision, recall, F1-score도 모두 91% 수준이었다. 다음 단계는 모델 성능을 더 올리는 것보다, 실제 서비스 입력에서 라우팅 실패가 얼마나 발생하는지 보는 것이다. 운영 데이터에서 치명적인 오분류가 쌓이면 데이터 증강이나 하이퍼파라미터 튜닝보다 먼저 클래스 묶음(class grouping)과 fallback 정책을 다시 본다.
